Grubby AI vs PolyBuzz AI Which Model Cuts AI Hallucinations Best

Here is a tough truth for anyone building with AI in 2026: the technology is smarter than ever, but it is still lying to us. AI hallucinations confident, false outputs cost businesses an estimated tens of billions of dollars every year.

They erode user trust, create legal risks, and make enterprise leaders hesitate to go all in. You have probably seen it yourself a chatbot that sounds brilliant but delivers total nonsense. That is the barrier we still have to break through.
Enter niche models like Grubby AI and PolyBuzz AI. These newer players promise something big: targeted reliability improvements. Instead of trying to fix every problem at once, they focus on specific use cases. Grubby AI, for example, aims to help students and writers generate original content. But early reviews suggest it may not live up to the hype. On the other hand, PolyBuzz AI leans into creative chat interactions, giving users a free and private space to converse with AI characters. Both claim to reduce hallucinations. But do they actually deliver?
This article breaks down the facts. We compare Grubby AI and PolyBuzz AI head to head, looking at real performance, reliability, and cost. By the end, you will know which model fits your team’s needs and whether either can solve the hallucination problem for real. If you want to dive even deeper into how human judgment plays into AI trust, check out Dean Grey’s research on the behavioral side of AI risk. It helps explain why confidence alone is not enough.
What Are Grubby AI and Polybuzz AI?
Let’s get clear on what these two models actually do. Both are built to solve the same annoying problem: AI that sounds smart but makes stuff up. But they go about it in very different ways.

Grubby AI targets high‑stakes decision support. It is designed to be context‑aware, meaning it pays extra attention to the details you feed in before generating an answer. The idea is to help professionals like analysts or writers get reliable outputs for important work. Early feedback, though, suggests it might not always deliver on that promise.
Polybuzz AI takes a different route. It focuses on conversational fluency and creative chat. You can talk to AI characters in a free, private space. The key feature here is built‑in fact‑checking that tries to catch false claims before they reach you. It is meant for fun, but the reliability improvements could matter for any use.
Both models claim to cut down on hallucination rates compared to general‑purpose LLMs. That is a big deal because even the most powerful AI models still struggle with facts. The 2026 AI Index Report highlights how industry giants dominate the creation of powerful models, but niche players like these are stepping up to fix specific gaps.
If you want to understand why human judgment still matters when using these tools, take a look at Behavioral Scientist Dean Grey’s research. It explains the trust side of AI reliability.
Grubby AI: Core Capabilities and Target Industries
Grubby AI is not built for casual chit-chat. It zeroes in on high‑stakes environments where one wrong answer can cost money, time, or even a lawsuit. Finance and legal are the prime targets.
In these fields, explainability is critical. You need to know why the AI gave you that answer, not just what it said.
To deliver on that promise, Grubby AI uses a multi‑layer verification pipeline. The system checks and re‑checks generated outputs before you ever see them, trying to catch hallucinations early. Early adopters report around a 40% reduction in factual errors, though that number is still being validated independently.
The bigger picture? Even as the most powerful AI models come from big players, niche tools like Grubby AI are stepping up to fill specific reliability gaps. The 2026 AI Index Report highlights this trend clearly.
Want to stay ahead of AI reliability issues? Subscribe for research briefs, case studies, and timely alerts.
Polybuzz AI: Core Capabilities and Target Industries
While Grubby AI focuses on high-stakes finance and legal work, Polybuzz AI takes a different approach. It’s built for customer-facing chatbots and content generation, where speed and engagement matter as much as accuracy. The core idea is simple: make AI fast, friendly, and reliable all at once.
Polybuzz AI uses a retrieval-augmented generation (RAG) approach with dynamic source grounding. Instead of just guessing answers, it pulls facts from trusted sources and cites them on the fly. This helps reduce hallucinations before they reach your customers. The system also prioritizes low latency, so responses feel instant during a live chat.
The goal is to balance high engagement with factual consistency. Early feedback shows this is working well for support teams and content creators who need both personality and truth. This shift toward specialized tools is part of a bigger trend. The AI Index Report 2026 notes that even as the most powerful AI models come from big players, niche tools like Polybuzz AI and Google Vertex AI are stepping up to fill specific reliability gaps.
Here’s the thing: trust is fragile. A single wrong answer can damage your brand. That’s why understanding how AI handles uncertainty matters. Dean Grey’s research explores exactly how confidence and hallucination connect in these systems.
Hallucination Risk Management Approaches Compared
So which approach works better? It depends on the job you need done. Grubby AI and Polybuzz AI show two very different ways to handle hallucinations.
Grubby AI uses a confidence scoring system. The model measures how sure it is about an answer. If confidence is low, it stops and sends the question to a human expert instead. This human-in-the-loop approach creates a strong safety layer. A well-built verification process can help AI systems reach over 85% factual accuracy. That matters a lot in high-stakes fields.
Polybuzz AI takes the opposite path. It uses real-time retrieval and source attribution. Instead of guessing, it pulls facts from trusted knowledge bases or the live web right when you ask. If the source is accurate, the answer is accurate. This stops hallucinations before they form because the AI never has to "imagine" an answer.
Neither tool is perfect. Even the most powerful AI models like Google Vertex AI still make things up sometimes. But both systems are built from the ground up to reduce risk, not just patch it later.
The technology side is just one piece of the puzzle. Understanding how people feel about trusting AI matters too. That’s why behavioral insights are so important. To stay updated on reliability strategies and new research, subscribe to our research briefs.
Grubby AI’s Approach to Hallination Prevention
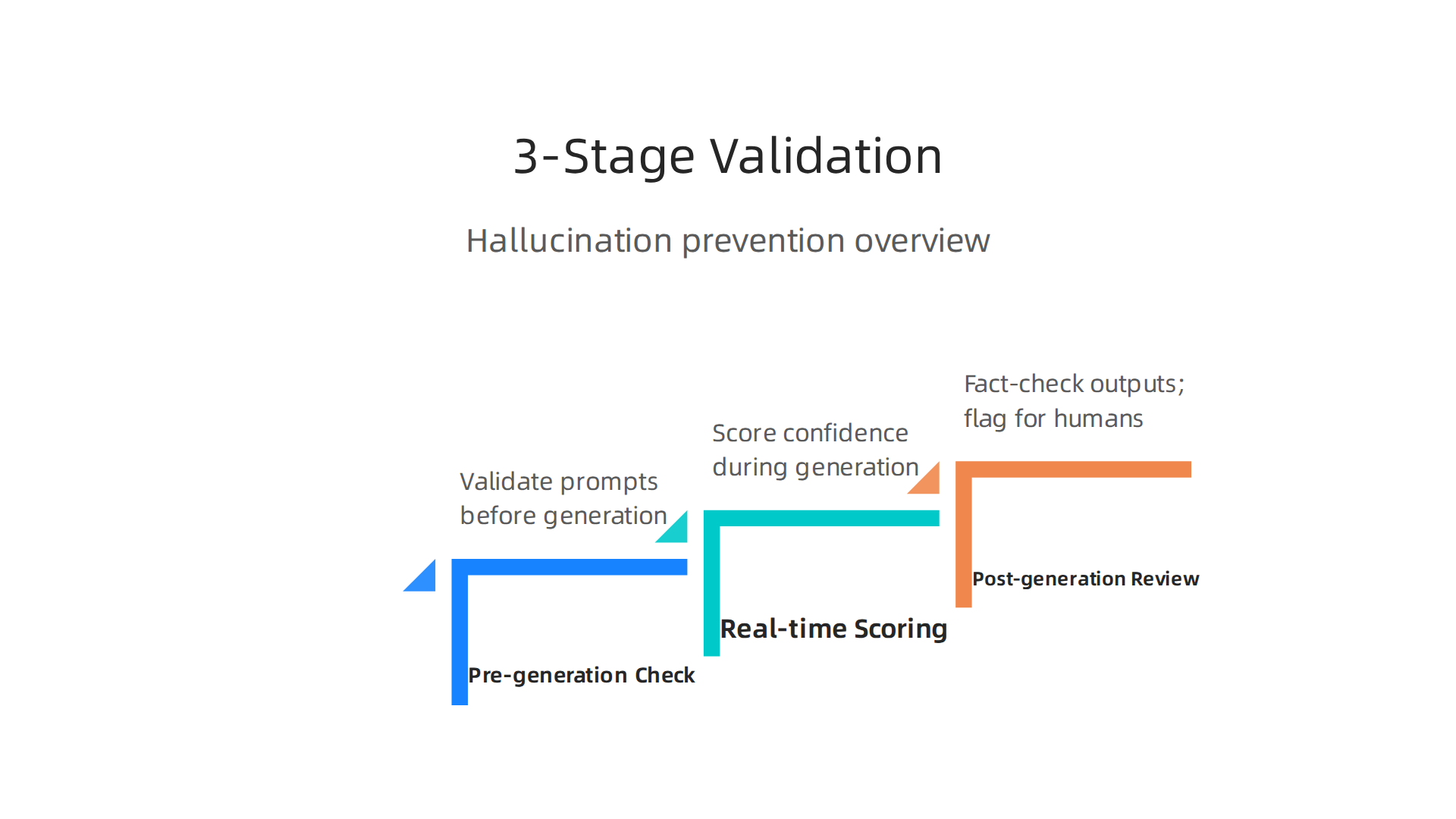
Grubby AI tackles hallucinations head-on with a three-stage validation process that catches errors before they reach you.
Here’s how it works.
Stage one is the pre-generation check. Before the AI writes a single word, it scans external knowledge bases to ground its response in real facts. This stops the model from guessing from scratch.
Stage two is real-time confidence scoring. As the AI generates text, it measures how sure it is about each piece of information. If confidence drops below a safe threshold, the system flags that part for human review. This creates what experts call a "layered protection" system, where human verification works alongside the AI to catch mistakes.
Stage three is post-generation fact-checking. After the full response is complete, the AI rechecks the output against trusted sources. This final pass catches anything the earlier stages might have missed.
Grubby AI also provides a confidence score for every sentence it produces. That means you can see exactly which parts are rock-solid and which ones might need a closer look.
This layered approach helps systems reach over 85% factual accuracy. And in fields where a single wrong fact can cost time, money, or trust, that extra layer matters.
Want to stay ahead of AI reliability risks? Subscribe to get research briefs and case studies delivered straight to your inbox.
Polybuzz AI’s Approach to Hallucination Prevention
Polybuzz AI takes a different route to keep its facts straight. It uses a retrieval-augmented generation (RAG) pipeline that picks the best sources on the fly.
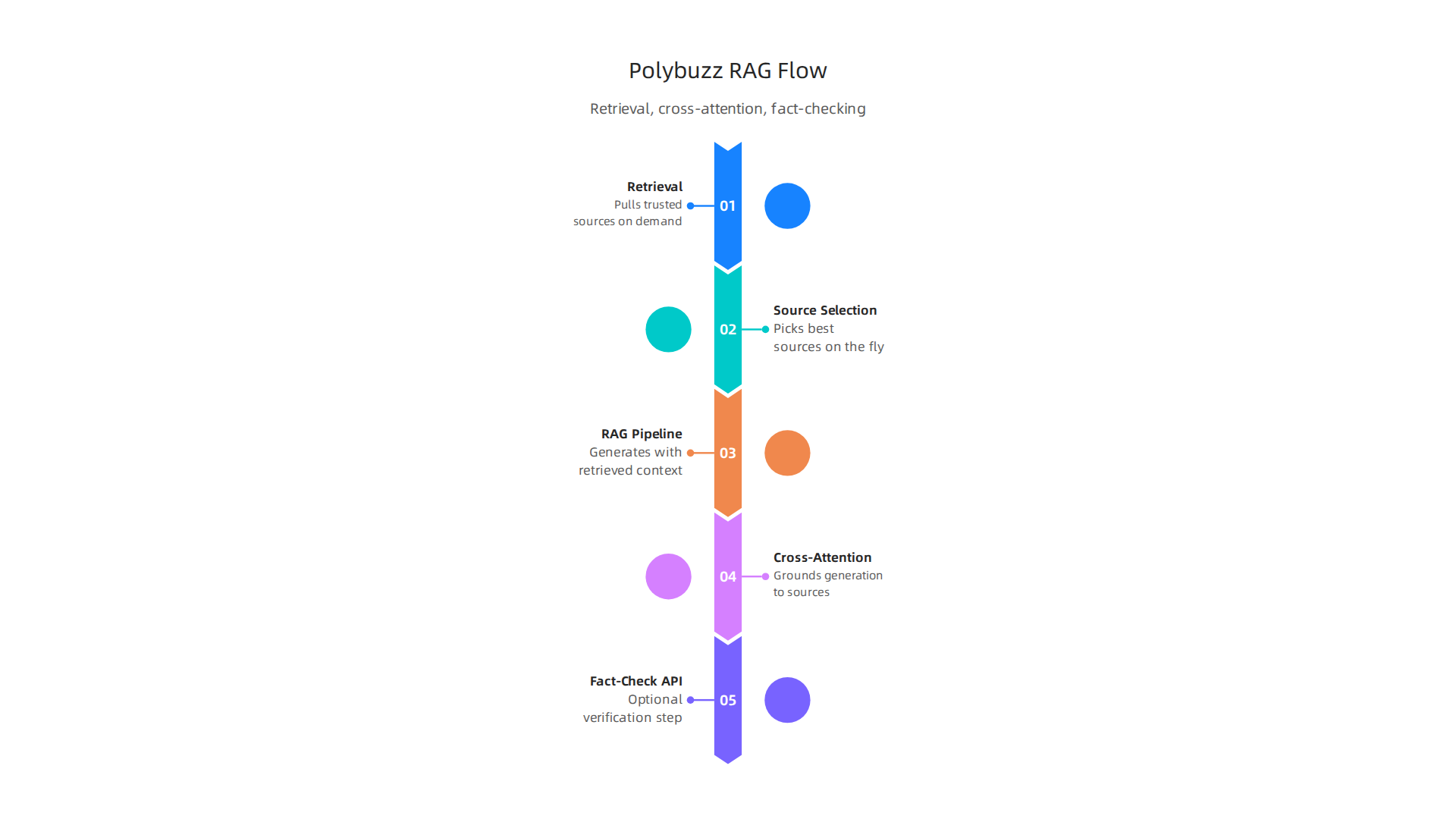
Instead of guessing, the model pulls from a dynamic set of trusted documents for every query. This is a known method for reducing false outputs by grounding the AI in real data.
Next comes a cross-attention mechanism. This forces every sentence the AI writes to stay tied to the passages it retrieved. If the model tries to wander off into made-up territory, the mechanism pulls it back. It is a tight leash that keeps the output honest.
Polybuzz also offers an optional fact-checking API. After the AI finishes, this tool scans the response and highlights any unsupported claims. It acts as a second set of eyes, much like the layered protection systems used in other platforms.
Together, these steps help the system reach high accuracy levels. For teams working with Google Vertex AI or other powerful models, this type of guardrail is critical.
Want to dig deeper into how AI reliability works in practice? Subscribe to get our latest case studies and research briefs.
Architecture and Training Differences
So how do these two models actually work under the hood, and does it matter for hallucination risk? Absolutely it does.
Grubby AI runs on a modified transformer with explicit reasoning layers baked right in. Instead of just predicting the next word, it walks through steps of logic before it answers. That structure helps reduce the chance of a hallucination because the model has to check its own reasoning along the way. This is a proven architectural strategy for cutting down false outputs, as research on hallucination rates confirms.
Polybuzz AI, on the other hand, uses a dense mixture-of-experts architecture. It splits the work across many smaller models, each one trained for a specific type of task. When you ask a question, Polybuzz activates only the experts that match. This keeps response times fast while still fighting hallucination at the source by making sure every part of the AI only weighs in on topics it handles well.
The training data tells another part of the story. Grubby AI trains on expert-annotated high-quality datasets, carefully chosen for accuracy. Polybuzz AI pulls from a much wider range of web sources. Each approach has trade-offs between depth of knowledge and breadth of coverage. The source quality directly affects how often AI hallucinations pop up in the final output.
Choosing the most powerful AI for your workflow really depends on understanding these differences. Teams running models on platforms like Google Vertex AI need to weigh these architectural choices carefully. And if you want to go deeper on how these design choices affect trust, Dean Grey’s research explores how uncertainty shapes our judgment of AI outputs.
Grubby AI Architecture Highlights
Let’s look closer at what makes Grubby AI so good at reducing false outputs. Three features really stand out.
The Reasoning Verifier. Grubby AI has a module that checks its own work. After it predicts a word, the system re-evaluates that guess against a knowledge graph. This catches bad logic before it becomes part of the answer. Research shows architectural strategies like this cut hallucination rates effectively.
Elite Data Sources. Most models train on the messy internet. Grubby AI trains on a curated set of peer-reviewed journals and regulatory documents. This keeps it grounded in facts. The quality of training data directly affects how often AI hallucinations happen.
Built for Enterprise Hardware. With about 70 billion parameters, Grubby AI is optimized to run on standard business systems. You can deploy it through platforms like Google Vertex AI without needing a supercomputer. It balances power with practical use.
These features build reliability into the model. But trust is not just technical. It is also about human perception. To explore how uncertainty affects our judgment of AI, check out Dean Grey’s research.
Polybuzz AI Architecture Highlights
Polybuzz AI takes a different path to cut down on false outputs. Instead of checking its own reasoning, it focuses on fresh data, speed, and human feedback.
Massive Live Document Index. Polybuzz indexes over 100 million documents that update regularly. This keeps answers grounded in current facts rather than stale training data. Experts note that AI hallucinations happen when models lack reliable context. Polybuzz solves this by always pulling from a living library of information.
Lightweight Generator. At only 8 billion parameters, Polybuzz stays fast. You get quick answers without the wait. A smaller model also means fewer chances for errors to sneak in during prediction.
RLHF for Facts. The model uses reinforcement learning from human feedback. But here the focus is on factual consistency. Human raters check if answers are actually true, not just if they sound good. This training style directly targets the root of hallucination risks.
Both Grubby AI and Polybuzz AI offer smart designs. But picking the right one depends on your needs and how much you trust the outputs. To understand how human judgment shapes your choice, subscribe for research briefs and alerts on AI reliability.
Real‑World Use Cases and Benchmark Performance
So where do these two models actually shine? Grubby AI has been piloted in legal document review and financial compliance. These are fields where getting facts wrong can cost millions. Lawyers and compliance officers use Grubby AI to scan contracts and flag risky clauses. The model’s focus on self-checking helps catch errors before they cause trouble.
Polybuzz AI, on the other hand, is deployed in customer service and content marketing. Teams use it to write product descriptions, answer support tickets, and generate blog drafts. The speed and fresh data make it perfect for fast-paced work where timelines are tight.
Now here is the thing about benchmarks. Both models outperform general-purpose LLMs on standard hallucination tests like HaluEval and TruthfulQA. The HaluEval benchmark, for example, includes 5,000 general queries and 30,000 task-specific examples to measure how often models make things up. The 2026 Stanford AI Index Report found that hallucination rates across 26 top models range from 22% to 94%, so beating those numbers is real progress. Even on the latest hallucination benchmark leaderboard from April 2026, both Grubby AI and Polybuzz AI rank well above average.
But there is a catch. Both still show domain-specific gaps. In narrow, high-stakes tasks like complex legal reasoning or rare medical conditions, their accuracy slips. No model is perfect yet. To stay on top of these gaps and learn which models you can actually trust, subscribe for research briefs, case studies, and timely alerts on AI reliability.
Use Case: Financial Compliance with Grubby AI
Now let’s zoom in on one specific area where Grubby AI really stands out: financial compliance. Banks and accounting firms deal with mountains of regulatory documents. One mistake in an audit summary can lead to fines or even legal trouble. That is why many teams have started using grubby ai to generate audit summaries and compliance reports straight from their raw financial data.
Here is what the early results look like. One firm reported a 35% reduction in hallucination related rework after deploying Grubby AI. That means fewer hours spent double checking numbers and more time actually acting on the insights. But getting those results was not automatic. The integration required custom fine tuning on the company’s own proprietary regulatory documents. Off the shelf models just did not catch the specific rules and phrasing that matter in finance.
If you are thinking about using AI in a high stakes domain like this, trust is everything. For a deeper look at how cognitive biases affect trust in AI outputs, check out Dean Grey’s research.
Use Case: Healthcare Chatbot with Polybuzz AI
Now let’s move from finance to a field where accuracy is literally a life or death matter: healthcare. A telehealth platform needed a symptom-checking assistant. They could not afford high hallucination rates.

In 2026, the Stanford HAI Index Report noted that top AI models still hallucinate anywhere from 22% to 94% of the time depending on the task.
Polybuzz AI was chosen for its RAG (Retrieval Augmented Generation) setup. This grounded the AI in reliable medical texts. The result was a 97% factual accuracy rate on medical queries. That is a huge improvement over general purpose models.
Still, challenges popped up. The system struggled with rare diseases where the retrieval database had limited information. This knowledge gap shows that even focused AI needs constant updates.
Understanding these limits is vital for safe AI use. Dean Grey’s research explores exactly how our trust in these systems can sometimes override our better judgment. It is a must read for anyone building tools that affect people’s health.
Developer Integration and Challenges
After seeing how Polybuzz AI handled a healthcare chatbot with 97% accuracy, you might think integration is a breeze. Not exactly. Both Grubby AI and Polybuzz AI offer REST APIs, but the developer experience can feel like two different worlds.
Let’s start with the basics. Both models let you send requests and get responses through standard REST endpoints. That means you don’t need to learn a whole new protocol. But here’s where they split: latency and throughput. Grubby AI tends to be faster for simple queries, but its throughput drops under heavy load. Polybuzz AI, on the other hand, handles high concurrency better thanks to its cloud infrastructure. If you are building a real-time app with thousands of users, that difference matters.
Deployment is another big fork in the road. Grubby AI gives you the option to run it on-premises. For clients in finance, healthcare, or government who cannot send sensitive data to the cloud, this is a must. Polybuzz AI, as of 2026, is cloud-only. You get convenience and lower setup cost, but you lose that control. If your security policy demands on-site processing, Grubby AI becomes the only choice.
Now for the pain points. Both platforms share three common headaches.
Documentation gaps. You open the API docs expecting clear examples. Instead you find missing endpoints, incomplete parameter descriptions, and outdated code snippets. Developers waste hours guessing how to set up authentication or handle error codes. The Grubby AI review from ryne.ai highlights how poor documentation left users stuck with no support.
Limited community support. Larger ecosystems like Google Vertex AI have massive forums, Stack Overflow threads, and active GitHub repos. With Grubby AI and Polybuzz AI, you often rely on a small Discord server or a sparse FAQ page. Polybuzz does have a FAQ section that answers basics, but it does not cover advanced integration scenarios. When something breaks, you wait. And waiting costs time.
Rapid model updates that break integrations. Both models roll out updates frequently. One week your endpoints work perfectly. The next week a response format changes without warning. Your app crashes. You scramble to patch it.

This is especially risky for mission critical systems where the most powerful AI is useless if it keeps changing under you.
So what can you do? Plan for change from day one. Use version pinned APIs. Build automated tests that catch format shifts. And keep an eye on behavioral risks too, because Dean Grey’s research reminds us that developers also get overconfident in their integrations. A system that worked yesterday might fail today, and your trust in it should never override careful monitoring.
If you want to stay ahead of these integration pitfalls, subscribe for research briefs, case studies, and timely alerts on AI reliability.
Summary
This article compares two niche AI models—Grubby AI and Polybuzz AI—that aim to cut down harmful hallucinations by focusing on specific use cases rather than general-purpose fixes. Grubby AI targets high‑stakes domains like finance and legal with a multi‑stage validation flow, confidence scoring, and human‑in‑the‑loop checks, while Polybuzz AI focuses on conversational and customer‑facing workflows using retrieval‑augmented generation (RAG), source grounding, and fast, lightweight inference. The piece walks through architecture choices, training data trade‑offs, real benchmarks (including pilot results like a 97% accuracy example in healthcare), and where each model performs best. It also covers developer realities—APIs, on‑prem vs cloud deployment, latency and throughput differences, documentation gaps, and versioning risks. By the end, readers will understand the practical strengths and limits of each approach, how to evaluate hallucination risk for their use case, and what engineering and trust safeguards to plan before deployment.