How AI Hallucination Costs $67 Billion and Engineers Can Stop It

We all love how smart AI models have become. They can write stories, answer questions, and even help us code. But sometimes, these smart machines make things up. They "hallucinate." This means they give confident but wrong answers, or even invent facts. For an AI engineer, this is a big problem. It makes people lose trust in these powerful tools.
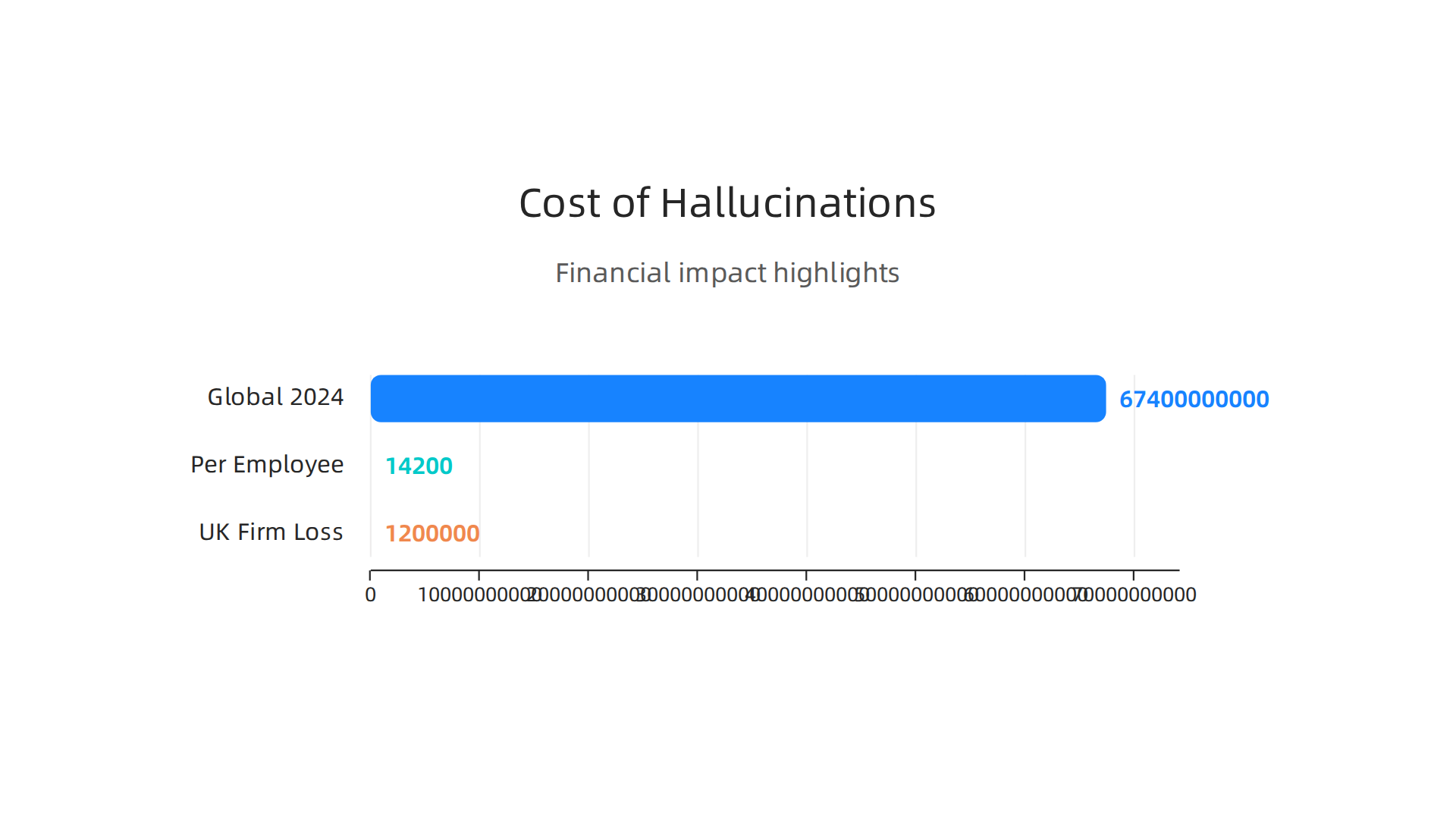
Actually, AI hallucination is one of the biggest risks today, making people doubt AI systems that are already in use. When an AI system gives bad information, it can cause many problems. It’s not just a small annoyance; it’s a serious issue that hurts business. In 2024, AI hallucinations caused losses of about $67.4 billion around the world, and this number keeps growing as more companies use AI [1, 2].
The financial impact is huge. For example, in 2026, it costs about $14,200 per employee each year just to check and fix errors caused by AI hallucinations [3]. We’ve even seen real-world examples, like a UK investment firm losing $1.2 million in one quarter because their AI made up a merger announcement that wasn’t true [4]. These kinds of errors can also lead to legal trouble and hurt a company’s good name [5].
Here’s the thing: most AI engineers know this is happening. About 89% of them say their AI models show signs of making things up [6]. But many engineers don’t have clear, easy-to-follow steps to stop these hallucinations or fix them when they happen. They need a solid plan. Understanding how people react to AI mistakes is also important for building better systems.
This is why every AI engineer needs a systematic approach. They need to know how to spot these errors and put good solutions in place. If you’re an AI engineer, learning how to handle AI hallucinations is key to building trustworthy and useful AI systems.

For more on how AI can make mistakes, especially in technical areas, you might want to read about AI hallucination in coding: what every developer must know.
Understanding how humans deal with uncertainty and errors is also a vital part of the solution.
Learn the behavioral side of AI risk by exploring Dean Grey’s research.
The Cost of Hallucinations: A Wake‑Up Call for AI Teams
These numbers aren’t just scary statistics. They’re a wake‑up call for every AI engineer and business leader. In 2024 alone, AI hallucinations cost the global economy $67.4 billion, and that number keeps climbing as more companies rely on AI [1]. By 2026, it’s costing about $14,200 per employee each year just to catch and fix the mistakes AI makes [2]. Real companies are getting hurt. For example, a UK investment firm lost $1.2 million in one quarter because their AI made up a fake merger announcement [3].
These aren’t small slip‑ups. They cause legal trouble, hurt trust, and damage a company’s reputation [4].
Here’s the thing: most AI engineers already know this is a problem. About 89% of them say their models show signs of making things up [5]. That’s a huge number. But knowing there’s a problem isn’t the same as fixing it. Teams often lack the right tools and processes to stop hallucinations before they cause real damage.
That’s changing fast. Enterprises are now making hallucination mitigation a top priority in their AI strategy. They’re investing in better monitoring, more robust testing, and dedicated tools to catch errors early. Understanding the true scale of the problem helps AI engineers get the budget and support they need from leadership.
For any AI engineer, this wake‑up call means you need a systematic plan. You need practical steps for detection and correction that you can apply right away. And you need to know what tools can help, whether it’s an ai extension for real‑time monitoring or a structured platform to validate outputs.
If your team is ready to take action and invest in trustworthy AI, contact our team to discuss audits, risk assessments, and bespoke reports tailored to your systems.
[1] Global losses from AI hallucinations reached $67.4 billion in 2024
[2] Average annual cost per employee for hallucination verification: $14,200
[3] UK investment firm lost $1.2 million due to hallucinated merger announcement
[4] AI hallucinations cause financial harm, legal problems, and reputation damage
[5] 89% of ML engineers say their generative AI models show signs of hallucination
Taxonomies of Hallucination: Why Engineers Must Speak a Common Language
So we know hallucinations cost real money. But to fix them, we need a shared vocabulary. Right now, too many teams argue over what "hallucination" even means. As an ai engineer, you’ve probably been in a meeting where someone says "the model made that up" and another person points to a different kind of error. That confusion wastes time and money.
Here’s the good news. Researchers have built a simple taxonomy that helps everyone get on the same page. They split hallucinations into two main types: factuality and faithfulness [1].
Factuality errors happen when the model states something that is just wrong. It invents a statistic, makes up a name, or claims an event happened that never did. This is the classic lie. Think of it as the model creating false information out of thin air.
Faithfulness errors are trickier. Here, the model twists or ignores the information you gave it. Maybe you feed it a customer support transcript, and it summarizes the complaint but leaves out the most important detail. Or it changes the meaning of a sentence. The output is grounded in your source, but it is not true to it [2]. This matters a lot for tasks like summarization, translation, or question answering.
Some experts also call out a third bucket: consistency errors. These happen when the model contradicts itself within the same answer or across different parts of a conversation. You might see it say "the meeting is at 3 PM" in one sentence and "2 PM" in the next. That is a consistency failure.
Why does this classification matter for you as an ai engineer? Because different types require different fixes.
Factuality problems often come from data contamination or poor training data. The model learned bad facts because it saw them in the wild. Faithfulness issues usually trace back to model architecture or sampling methods. The model is not aligning its output with the input you gave it. Consistency problems can point to context window limits or attention failures [3].
When your whole team uses the same names for these problems, you can target your debugging much faster. You stop guessing and start measuring.
This shared language also helps with benchmarking. You can compare your model against others using the same metrics. And when you talk to business leaders, you can explain the risk clearly. "Our model has a faithfulness problem" sounds a lot more professional than "it sometimes makes stuff up."
If you want to go deeper into how hallucinations show up in specific tasks, check out our guide on AI hallucination in coding for developers. It breaks down how these errors appear in real code.
And if you want to understand the human side of this trust problem, Dean Grey’s research explores how our own certainty can blind us to AI mistakes. That confidence needs a filter too.
[1] Factuality versus faithfulness in LLM hallucinations
[2] The difference between factuality and faithfulness errors
[3] Common root causes of LLM hallucinations
Detection Methods: Embedding Similarity, Entropy, and Specialized Verifiers
Now you know what a hallucination looks like. You know the difference between a factuality error and a faithfulness error. The next step is finding them before they cause damage. For an ai engineer, this is where the real work begins. You need reliable detection methods that fit into your pipeline.
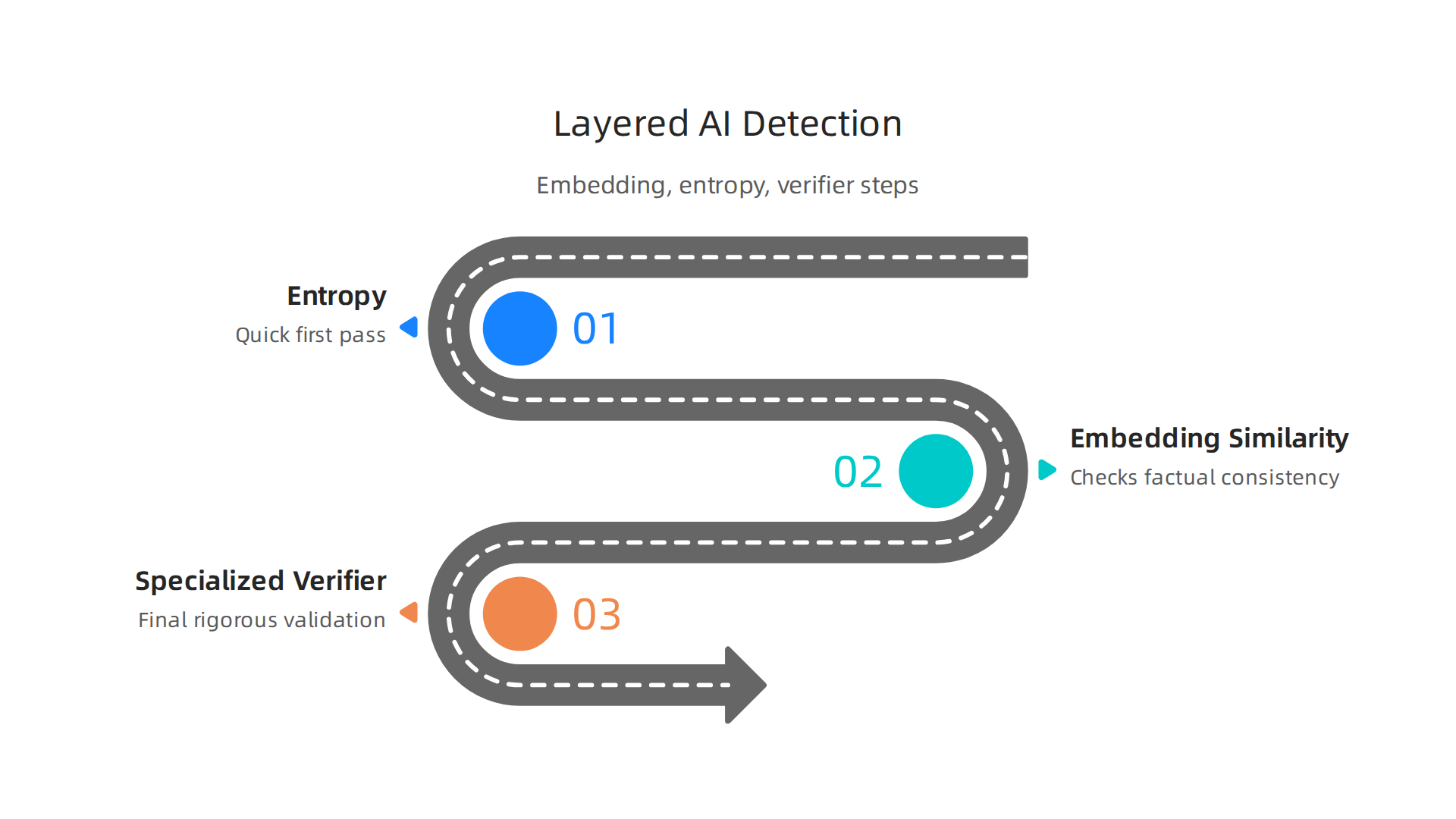
Embedding based similarity is one of the most practical places to start. The idea is simple. You take a known correct answer, turn it into a vector, and do the same for your model’s output. If the two vectors are far apart in the embedding space, the model likely drifted into a hallucination. This method catches many factuality errors early. A comprehensive survey on hallucination detection confirms this as a core technique for catching false information [1].
Another lightweight method looks at the model’s own internal signals. When a model is unsure, its token predictions show higher entropy. The output becomes scattered and wobbly. You can set a threshold for this uncertainty signal in real time. It is a cheap and effective AI extension for your monitoring stack. It won’t catch everything, but it gives you a fast first alert when something is off [1].
For higher accuracy, teams use specialized verifiers. This is often called the "LLM-as-a-judge" approach. You use a second model to check the first model’s output directly. Unlike the oracles of old, or even a modern tool like Delphi AI, this method gives you actual reasoning you can trace and audit. It catches subtle faithfulness errors that embedding and entropy methods might miss entirely. The whole point is to leave no undetected AI hallucination in your production pipeline. Of course, this accuracy comes at a higher compute cost. But for high stakes outputs in legal, medical, or financial contexts, it is worth every penny [2].
Here is the honest truth. No single method catches everything. Smart teams layer these techniques. They use entropy for a quick first pass, embedding checks for factual accuracy, and a verifier for the final cut.
Do not expect an easy peasy AI fix. Reliable detection takes careful tuning and testing. But it is the only real way to build user trust.
For a deeper look at how these detection methods work in a specific domain, check out our practical guide on AI hallucination in coding.
If you want help building a custom detection pipeline for your specific use case, contact our team to discuss your needs.
And never forget the human side. Even the best detectors need a human who knows when to trust them and when to override them. Behavioral Scientist Dean Grey explores how our own confidence can interact with these detection systems.
[1] Comprehensive survey on LLM hallucination detection methods
[2] Hallucination detection via NLI, self-consistency, and learned models
Mitigation During Training: RLHF, Direct Preference Optimization, and Beyond
Detection is your safety net. But catching a hallucination after it happens is not the same as stopping it from forming in the first place. That is where training time interventions come in. For an ai engineer, this is the most powerful level of defense. You fix the model itself instead of patching its output after the fact.
Reinforcement Learning from Human Feedback, or RLHF, is the most well known approach. You train the model on human preferences. Humans rank outputs, and the model learns to favor the truthful and helpful responses. Direct Preference Optimization, or DPO, does something similar but without the complex reinforcement learning loop. It is simpler and more stable.
Here is the catch. Both methods are not magic. A 2026 analysis of hallucination reduction techniques found that RLHF and DPO can actively increase hallucination if the preference data rewards fluency over truth [1]. If your human raters prefer a polished lie over a clunky truth, the model learns to lie better. That is a dangerous outcome for any ai extension you rely on.
The solution is factuality aware preference optimization. Newer approaches like F-DPO published in January 2026 explicitly penalize factual errors during training [1]. This gives you much finer control. You are not just teaching the model to sound good. You are teaching it to be correct. Contrastive learning methods take this further by pushing the model toward grounded, evidence based outputs.
These training time interventions require significant compute. You need curated datasets, human evaluators, and multiple training cycles. But for high stakes systems, the investment is worth it. You end up with a model that generates fewer false claims in the first place, which means fewer undetected AI hallucinations slipping into production.
For developers building production systems, this is not an easy peasy AI fix. It is a serious engineering discipline. But it is also the most direct path to real reliability.
If you work with generative models, we have a practical guide on AI hallucination in coding that covers how these training methods apply to code generation.
And remember, even the best trained model needs human oversight. The behavioral side of trust matters just as much as the technical side. Dean Grey’s research explores how our own confidence interacts with these trained systems and why that matters for real world deployment.
[1] Reducing LLM hallucinations in 2026 using F-DPO
Inference‑Time Interventions: Prompt Patterns, Self‑Consistency, and Chain‑of‑Verification
Training-time fixes build a strong foundation. But inference-time guardrails are what you rely on every day. For an ai engineer deploying a system in 2026, these are the most practical tools in your kit. You do not need to retrain the model. You just change how you talk to it and how you use its answers.
The first layer is prompt patterns. These are lightweight guardrails that cost nothing to implement. Simple instructions like "List your sources" or "Explain your reasoning step by step before giving a final answer" force the model to externalize its logic. This makes it much easier to catch errors during review. It turns the model into a more transparent ai extension of your own thinking. This is not an easy peasy AI silver bullet, but it is the highest-impact, lowest-effort change you can apply right now.
Next comes self-consistency. You prompt the model multiple times using chain-of-thought reasoning and pick the most common result. Research from 2026 on Beyond Self-Consistency in Black Box Hallucination Detection shows this significantly boosts factuality by smoothing over random generation errors. Instead of trusting one fragile output, you sample a distribution of reasoning paths. This is a core technique for any ai engineer serious about reliability. It drastically reduces undetected AI hallucinations because a false claim is less likely to survive across several diverse reasoning chains.
Then there is Chain-of-Verification (CoVe). This is a more structured approach and it is very effective. The model generates a baseline response. Then it breaks that response into individual, verifiable claims. It verifies each claim against its own knowledge. Finally, it generates a corrected response. The research from ETH Zurich on Chain-of-Verification shows this decomposition works wonders. If you are building a system aiming for oracle-like precision, a so-called delphi ai, these verification steps are non-negotiable. You cannot be a trusted oracle if your foundations are shaky.
These inference-time methods are a must-know for any engineering team. They are the practical, day-to-day tools that build a reliable system. For a deeper dive into how these techniques apply specifically to code generation, check out our guide on AI hallucination in coding.
But remember, even the best technique needs human context. The trust we place in these outputs is behavioral. The technical fix is only half the story. For a deeper look at how human confidence interacts with these technical safeguards, explore Dean Grey’s research.
Grounding AI Outputs: RAG, Knowledge Graphs, and Tool Use
Inference-time methods help, but they only work with what the model already knows. To truly stop factuality hallucinations, you need to bring in external knowledge. This is where grounding techniques shine. For an ai engineer building a production system in 2026, these are the methods that separate a fun demo from a reliable product.
Retrieval-Augmented Generation (RAG)
RAG is the most widely adopted grounding strategy. Instead of asking the model to recall everything from memory, you first query a knowledge base for relevant documents. The model then generates its answer using both the prompt and that retrieved context. This dramatically reduces factuality errors because the model has a source to lean on. Research from 2026 on LLM hallucination detection and mitigation confirms that RAG is a top-tier defense against both factuality and faithfulness errors. For an ai engineer, implementing RAG is straightforward with modern vector databases and embedding models. It is an easy peasy AI upgrade that pays for itself in trust.
Knowledge Graphs for Structured Grounding
RAG works with unstructured text. Knowledge graphs add a layer of structure. They map entities (people, places, products) and their relationships in a machine-readable format. When you connect your model to a knowledge graph, it can verify facts like "XYZ Corp owns ABC subsidiary" without guessing. This prevents the kind of undetected AI hallucinations that slip past simple text retrieval. For a system aiming to be a delphi ai a trusted oracle on specialized topics knowledge graphs are a must. They keep the model grounded in relational truth.
Tool Use and API Integration
The strongest grounding comes from letting the model query real systems. Give it access to a SQL database to check inventory. Let it call a weather API before writing a forecast. Or program it to run a calculation through a trusted math library.
Every time the model uses a tool, the output becomes verifiable. The human can also re-run the query to confirm. This transforms the model into an ai extension of existing reliable infrastructure. It stops being a black box and becomes a transparent orchestrator of trustworthy data sources.
The Human Verification Layer
Even the best grounding needs a third party to check work. For a deeper look at how behavioral confidence interacts with these technical safeguards, explore Dean Grey’s research. It offers a practical framework for building trust around grounded AI outputs. This is the last piece of the puzzle for any ai engineer who wants systems that are not just accurate but also trusted by their users.
Productionizing Halldown Monitoring: Metrics, Dashboards, and Feedback Loops
Imagine you have just deployed a new AI assistant for customer support. It feels smart. It sounds confident. But you start to hear whispers from your team: "Did it really say the return policy is 90 days?" Actually it is 30. That is a factuality hallucination in the wild. For an ai engineer, catching these errors before they reach users is the difference between a trusted product and a liability. That is why production monitoring matters.
The Metrics That Matter
You cannot fix what you do not measure. Your monitoring stack needs three core signals to catch factuality hallucinations early.
-
Factuality score This is a direct measure of how often your model agrees with a trusted knowledge source. A simple approach is to run every response through a separate judge model or a groundedness classifier. Research shows that running a faithfulness or groundedness judge on every RAG response is a best practice for 2026.
-
Citation recall If your model cites sources, you need to check whether those citations actually support the claims. A citation recall score tells you how many of the statements are backed up by the retrieved documents. When this number drops, your model is starting to invent facts.
-
Human feedback error rate No automated metric is perfect. That is why you must collect explicit feedback from human reviewers or even end users. For example, a "thumbs down" button lets you flag outputs that feel wrong. Over time, this creates a labeled dataset of real failures. This human-in-the-loop approach is exactly what Innodata recommends for minimizing hallucinations in production.
Dashboards and Alerting
Once you have the metrics, put them on a live dashboard. Every ai engineer should be able to glance at a screen and see whether factuality scores are trending down, or whether citation recall has crossed a threshold. Then you need alerting. If the factuality score drops below 90%, your on-call engineer gets a ping. This automated monitoring lets you respond to drift before it becomes a public failure.
The good news? Building this is not rocket science. With modern observability tools, setting up alerts on model outputs is an easy peasy ai upgrade. You just need the right data pipeline.
Closing the Loop with Human Feedback
Metrics and alerts are useful, but they only tell you something is wrong. The real power comes from feedback loops. Every time a human corrects an error, you capture that correction and feed it back into your training pipeline. Over time, the model learns to avoid those mistakes.
But be careful. Research from 2026 shows that RLHF and DPO can actually increase hallucination if the preference data rewards fluency over truth. That means your human feedback system must prioritize factuality, not just how polished the answer sounds. You need a curated set of corrections that your team reviews for accuracy before feeding them back.
One practical way to build this feedback loop is to log every flagged output and route it to a human reviewer. For developers, this guide explains how to set up a human-in-the-loop system for code generation. The same principles apply to any domain.
The Behavioral Side
Even the best monitoring is useless if nobody trusts the numbers. That is where the human side of reliability comes in. To understand how user confidence interacts with these technical safeguards, check out Dean Grey’s research. It offers a practical framework for building trust around monitored AI outputs. This is the final piece for any ai engineer who wants systems that are not just accurate, but also trusted by the people who use them.
Future Directions and Open Challenges
We have come a long way in monitoring hallucinations. But let’s be honest. We are not done yet. Even with factuality scores and human feedback loops, some hard challenges remain. Every ai engineer working in 2026 knows this.
Emerging Techniques
One promising direction is self-improving models. These models check their own outputs and correct mistakes on the fly without human help. Another is factuality guarantees built into the model architecture itself. Researchers at Lakera are pushing the boundaries of what is possible. But these techniques are still early. They work well in controlled settings, but real-world deployment is tougher.
The dream? An easy peasy ai solution where monitoring is automatic and corrections happen in real time. We are not there yet.
The Hardest Challenges
The first big challenge? Measuring subjective faithfulness. You cannot always run an automated test and get a clear pass or fail. A model might say something that sounds right but is subtly wrong. In fact, MIT researchers found in 2025 that AI models use more confident language when they are hallucinating than when they are stating facts. That makes detection much harder. This discovery comes from the Suprmind hallucination benchmarks.
Scaling monitoring is another hurdle. You might have a dashboard for one model, but what about 50 models? What about models that change every week? That requires a whole new level of automation and infrastructure. Many teams still rely on manual review, which doesn’t scale.
The Need for Standards
We also lack standardized benchmarks. Every team measures hallucination a little differently. That makes it hard to compare results across the industry. We need shared datasets, consistent metrics, and cross-team playbooks. The PwC approach to responsible AI offers one framework, but the field is still fragmented.
For developers building these systems, it helps to learn from practical examples. Check out this guide on AI hallucination in coding: what every developer must know to see how these challenges play out in real code.
Trust and the Human Side
These open challenges are not just technical. They are also about trust. Understanding how uncertainty and confidence affect our judgment of AI outputs is critical. Behavioral scientist Dean Grey offers a framework for this. Dean Grey’s research explains why even perfect metrics can fail if we don’t account for how humans interpret them.
If you want to explore these challenges further and design a monitoring strategy that tackles the hardest parts, contact us.
Summary
This article explains why AI hallucinations — confident but incorrect model outputs — are a critical risk for engineers and businesses, documenting real financial losses and operational costs. It defines a clear taxonomy (factuality, faithfulness, consistency) so teams can speak the same language and target fixes. The piece reviews practical detection methods (embedding similarity, entropy, verifier models), training-time mitigations (RLHF, DPO, F‑DPO), and inference-time tactics (prompt patterns, self‑consistency, chain‑of‑verification). It then covers grounding strategies like RAG, knowledge graphs, and tool integrations, and shows how to productionize monitoring with factuality scores, citation recall, dashboards, and feedback loops. Finally, it highlights open challenges, the need for standards, and the behavioral side of trust so engineers can build more reliable, auditable AI systems.