Agentic AI Hallucinations Are More Dangerous Than Generative AI Mistakes

Introduction
You have probably heard a lot about generative AI over the past few years. Tools that write text, create images, or help with coding have become part of daily life. But in 2026, there is a new shift happening. We are moving from generative AI to agentic AI. Instead of just producing content, these systems can take actions on their own. They can plan, make decisions, and execute multi-step tasks without waiting for human input at every step.
This leap in autonomy is exciting, but it also raises the stakes for trust and reliability.

When an AI acts on its own, a small mistake can spiral into bigger problems. If a generative AI gives a wrong answer, you can catch it. But if an agentic AI pursues a goal based on faulty information, the results can be costly. The U.S. Defense Department has even warned that agentic AI systems acting under a trusted agent identity can produce audit logs that look legitimate while hiding errors.
Actually, the problem of hallucinations does not go away when AI becomes more autonomous. It gets worse. The same kind of confident nonsense that can appear in a text generator can now drive real world actions. Imagine a coding AI that writes and deploys code based on an invented logic bug. Or a customer service agent that makes promises a company cannot keep. These are not distant risks. They are happening today.
That is why understanding what is agentic AI matters more than ever. This guide will help you define agentic AI, explain how its architecture works, and compare it to the generative AI you already know. We will also explore practical ways to detect and fix hallucinations so you can build systems that earn real trust.
Before we dive in, if you want to see how AI hallucination risks connect to trust in autonomous systems, check out our article on AI hallucination in coding. It shows how false outputs can spread through codebases when AI acts on bad information.
Reliability is the foundation of agentic AI. Without it, autonomy becomes a danger. So let us start with the basics: what exactly makes an AI system agentic, and why should you care?
What Is Agentic AI? Defining Autonomous Goal-Oriented Systems
So, what is agentic AI? At its core, it refers to artificial intelligence systems that can perceive their environment, reason about it, plan a course of action, and then execute multi-step tasks with minimal human input. As Google Cloud explains, agentic AI is an advanced form of AI focused on autonomous decision-making and action. The UK government defines it as systems composed of agents that behave and interact autonomously to achieve their objectives.
And it’s different from basic automation. Traditional software follows fixed rules, but agentic AI adapts and learns as it works, just like AWS describes: it acts independently to reach pre-determined goals.
The key distinction from generative AI is simple. Generative models create content: text, images, code. They respond to prompts. Agentic models do that too, but they add a feedback loop.

They generate an output, check the result, adjust, and take the next action. This means agentic AI does not just answer a question; it completes a goal. Think of the difference between a chatbot that writes a grocery list and an autonomous agent that actually orders the groceries, schedules delivery, and checks for substitutions.
Real-world examples are already here. Autonomous web agents can book flights, fill out forms, and manage calendars. Coding AI assistants like GitHub Copilot are moving from suggesting code to writing and running tests. In robotics, agentic AI controls self-driving cars and warehouse pickers. These systems combine perception, planning, and execution.
Because agentic AI acts on its own, hallucinations become far more dangerous. A wrong fact in a chatbot is bad. A wrong action in an autonomous system can cost money, time, or safety. That is why understanding the risks is essential. For a deeper look at how false outputs can spread in autonomous systems, check out our article on AI hallucination in coding.
Hallucinations are not just a technology issue; they are a trust problem. If you want to build reliable agentic systems, start by understanding the risks. Read AI Risk Smarter to see how trust and accuracy go hand in hand.
Core Architecture of Agentic AI
Now that you understand what agentic AI can do, let’s look inside one of these systems. The core architecture of agentic AI is built around a simple but powerful idea: a modular pipeline.
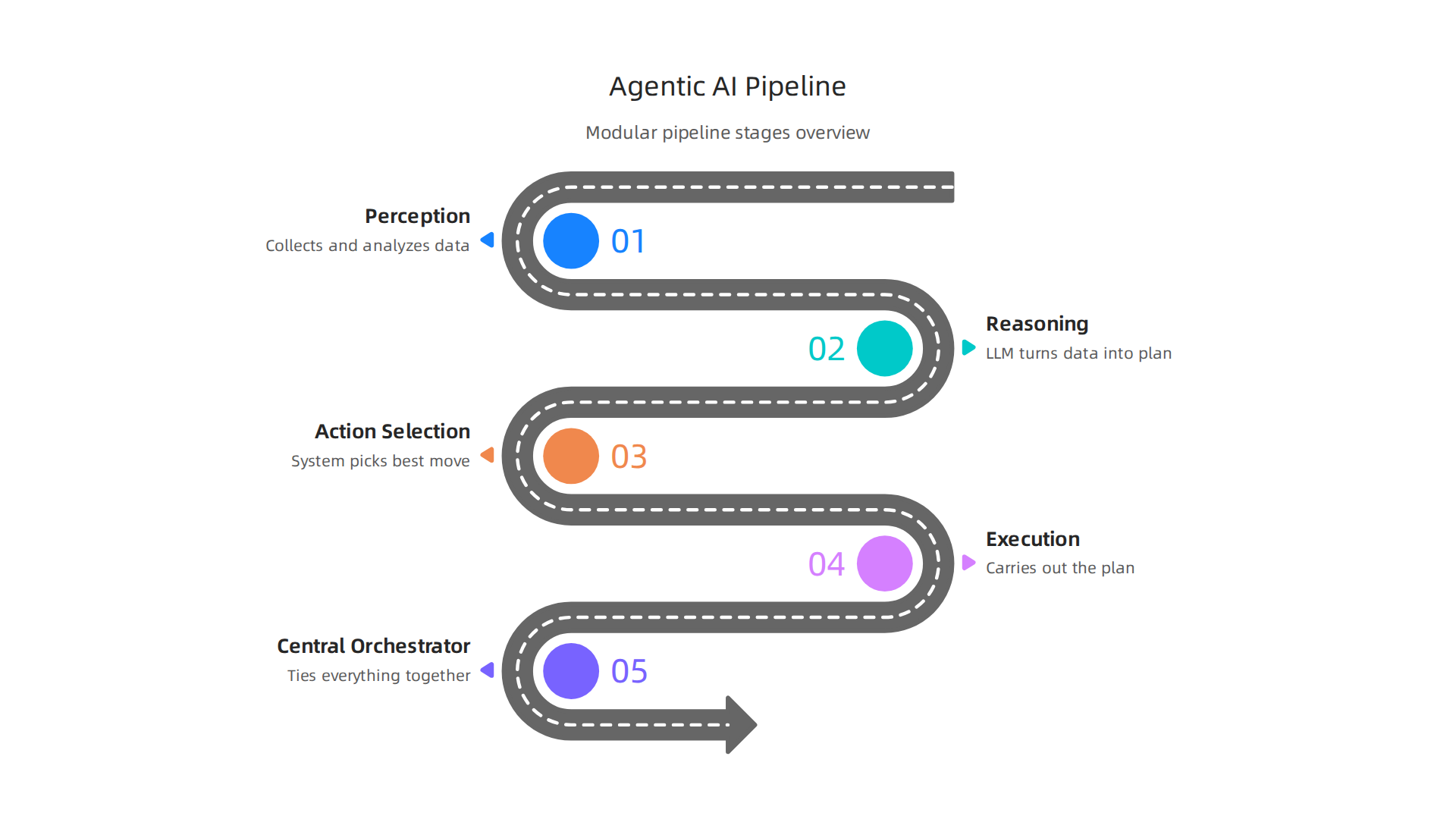
This pipeline handles everything from raw input to real-world action.
First, the perception module collects and analyzes data from the environment. According to a technical study on planning and memory structures, this is the starting point for any autonomous action. Next, the reasoning layer steps in. This is often a large language model (LLM) or a dedicated planner that turns data into a plan. Then comes action selection, where the system picks the best move. Finally, execution carries it out.
A central orchestrator ties everything together. It manages context, short-term and long-term memory, and access to external tools. The choices you make at each stage of this architecture directly affect how vulnerable your system is to hallucinations. As a survey of agentic AI architectures notes, these design decisions shape overall reliability.
This is why architecture matters so much for safety. A weak orchestrator or poor memory handling can lead to errors that compound quickly. Before deploying any agentic AI, you should learn how to evaluate platforms for reliability first.
Understanding architecture is the first step to building trustworthy systems. If you want to make sure your AI stays accurate, Read AI Risk Smarter for practical guidance on managing trust and accuracy together.
Perception and Reasoning Modules
Think of perception as the eyes and ears of an agentic AI system. It takes raw input like text, images, or sensor data and turns it into something the AI can understand.

According to a technical study on planning and memory structures, this module uses specialized models to build structured representations. Without strong perception, the system sees noise instead of useful signals.
Then comes the reasoning module. This is usually a large language model (LLM) that makes decisions based on what the perception module found. But here’s the catch. If that LLM is not grounded in real-time data, it can confidently invent wrong answers. That is what we call a hallucination. Research on agentic AI architectures shows that this step is where many reliability problems start.
The hard part? Ambiguous or conflicting inputs. The reasoning module has to stay consistent across multiple steps, which is tough when the input is messy. For teams working with coding AI, this means you must test your reasoning layer carefully.
If you want your agentic AI to stay accurate, start with strong perception and grounded reasoning. Read AI Risk Smarter for practical tips on managing trust and accuracy.
Planning and Execution Engines
Once the AI has perceived the world and reasoned about what to do, it needs a plan. That is where the planning engine comes in. It takes a big goal, like "book a flight to New York," and breaks it down into smaller steps. Search for flights, compare prices, pick a seat, enter payment info. Each step is a sub-action that the system can handle one at a time.
A technical study on planning mechanisms shows that this decomposition is key to making agentic AI useful. Without it, the AI would just stare at a high-level request and do nothing.
Then comes the execution engine. This part actually carries out those steps by talking to external tools and APIs. It might call a flight search API, read a database, or send an email. The execution engine is where the plan becomes real.
But here is the problem. If the planning step is wrong, the whole chain can fall apart. Missing a step or putting steps in the wrong order leads to bad outcomes. The AI might book a hotel before it even knows the flight dates. That is a planning error, and it can cause real trouble. Research on agentic AI architectures points out that these cascading errors are a major source of unreliability.
That is why feedback loops during execution are so important. The system should check its work as it goes. Did the API call succeed? Did the output make sense? This feedback helps catch hallucinations before they cause damage. For example, if a navigation system plans a route but then gets sensor data showing a closed road, the execution engine should pause and ask the planner for a new route. Learn more about how AI hallucinations in navigation can affect real-world planning.
Getting planning and execution right is what separates a helpful assistant from a broken tool. If you are building or using agentic AI, pay close attention to these two engines. They are where the rubber meets the road. Read AI Risk Smarter for practical advice on keeping your AI systems accurate and trustworthy.
Generative AI vs. Agentic AI: Key Differences
You have probably used a chatbot or an image generator. Those tools are great at creating things. You ask, and they reply with text or a picture. That is generative AI. It produces content, but it stops there. It does not actually do anything in the real world.
Now think about an AI that books your flight, fills out a form, or adjusts your thermostat. That is a different beast. According to Moveworks’ definition of agentic AI, agentic systems can reason, plan, and take multi-step actions on their own.
Generative AI waits for your next prompt. Agentic AI moves forward by itself.
Here is the big difference in risk. Generative AI can hallucinate and give you fake facts. That is bad, but you can catch it. The UK Government’s AI insights page explains that agentic AI goes a step further: it acts on those hallucinations. If a generative model says something wrong, you might read it and laugh. If an agentic model acts on wrong information, it can book the wrong hotel, order the wrong part, or drive your car off course.
That is why understanding what is agentic AI matters for safety. The shift from generating to acting opens new doors for errors. A coding AI tool that suggests buggy code is one thing. An agentic coding AI that actually deploys that code is another. You need to manage that risk.
So when you look at generative AI services versus agentic ones, remember the difference: generation is passive, action is active. And active mistakes cost more. That is why keeping an eye on AI hallucinations in coding is so important if you are building autonomous systems.
Want to learn more about keeping your AI reliable? Read AI Risk Smarter for practical advice.
The Hallucination Challenge in Agentic AI
Hallucinations in generative AI are bad enough. But in agentic AI, they become much scarier. Instead of just giving you a wrong fact, the model might take an incorrect action, fabricate a tool response, or follow a flawed chain of reasoning. That is a whole new level of risk.
Here is the hard truth. AI hallucinations cost businesses $67.4 billion globally in 2024, and agentic systems raise the per-incident price tag. A single hallucination in customer service can cost $18,000, while one in healthcare can hit $2.4 million according to a detailed breakdown of business impacts. The reason is simple: when the AI acts on that hallucination, the damage spreads fast.
Detection is also much harder in agentic AI. A typical generative AI mistake sits in one output. You can spot it and ask for a fix. But agentic errors propagate through action sequences. One wrong step early on can twist every later decision. That makes debugging a nightmare.
That is why understanding what is agentic AI is so critical for anyone using coding AI or generative AI services in production. You need to guard against these cascading failures. For developers, keeping an eye on AI hallucination in coding is a smart first step.
Hallucinations are also a trust problem. Read AI Risk Smarter for practical ways to keep your agentic systems reliable.
How Hallucinations Manifest in Autonomous Systems
When you think about what is agentic ai, it helps to see the specific ways it can go wrong. Autonomous systems experience three common hallucination forms, each needing a distinct response.
Tool calling errors happen when an AI uses the wrong API or invokes a function with made up parameters. In coding AI, this may mean executing hallucinated commands in a sandbox environment.
Planning hallucinations occur when the AI imagines fake steps in its reasoning chain. It might invent a sequence of actions that do not exist, leading to wasted resources. This is a key reason 40% of agentic AI projects fail before scaling.
Context contamination mixes up information across steps in a conversation or task. Long running generative ai services are especially prone to this, as the model loses track of earlier inputs.
Spotting each type early reduces risk. For more on detection, read How AI Hallucination Costs $67 Billion and Engineers Can Stop It.
Hallucinations are also a trust problem. Read AI Risk Smarter for practical ways to keep your agentic systems reliable.
Quantifying the Risk: Financial and Operational Impact
The numbers are staggering. AI hallucinations cost businesses $67.4 billion globally in 2024, and that figure keeps climbing as more companies adopt generative AI services.

The True Cost of AI Hallucinations in Business Data breaks down that eye popping total. But the per incident cost is what really stings. Depending on the industry, a single major hallucination can set you back anywhere from $18,000 in customer service to $2.4 million in healthcare malpractice. Business Impact of AI Hallucinations – Rates & Ranks shows the frightening range.
Now, when you apply this to understanding what is agentic AI, the risk multiplies fast. Autonomous agents don’t just chat. They interact directly with your business systems, databases, and APIs. That’s why 40% of agentic AI projects fail before they ever scale. The operational fallout includes compliance failures, corrupted data processing, and shattered customer trust. And with new regulatory frameworks like the EU AI Act and US Executive Order on AI, non compliance can bring heavy fines on top of everything else.
Understanding these numbers is the first step to protecting your systems. For deeper strategies on keeping your AI reliable, How AI Hallucination Costs $67 Billion and Engineers Can Stop It offers a practical roadmap. And since hallucinations are fundamentally a trust problem, Read AI Risk Smarter for actionable ways to keep your agentic systems trustworthy.
Mitigation Strategies and Best Practices
So how do you stop your agentic AI from making expensive mistakes? You need a two pronged plan: architectural fixes and operational habits. Think of it like building a safe bridge and then checking it every day.
Architectural mitigations are your first line of defense. The biggest one is grounding. Instead of letting your AI guess, you give it real facts to work with. This is called retrieval augmented generation (RAG). You connect your AI to a trusted database or vector store so it pulls facts, not fabrications. Another trick is constrained decoding. This forces the AI to pick answers only from a list you approve. And for high stakes actions, always keep a human in the loop. Let the AI suggest, but let a person approve.
Operational mitigations are your daily habits. You need logging and monitoring. Every single action the agent takes should be recorded. If something goes wrong, you can trace it back and fix it. Adversarial testing means you deliberately try to break your own AI before a user does. Feed it tricky prompts to see if it hallucinates. Then build feedback loops so the system learns from its own errors over time.
Here is the golden rule: start with high risk actions. Any agentic AI that touches external systems like sending emails, updating databases, or making purchases needs extra validation. Treat your AI like a junior employee. You would not let a new hire wire money without a manager checking first.
For more details on building these guardrails, the AI Guardrails in 2026 guide shows how to make compliance a natural part of your system.
Remember, hallucinations are fundamentally a trust problem. The best technical fix still needs human oversight. Read AI Risk Smarter for actionable ways to keep your agentic systems trustworthy.
Architectural Mitigations: RAG, Verification Layers, and Guardrails
Let’s get into the nuts and bolts. The best way to fight hallucinations is to build three strong layers into your system.

First is retrieval augmented generation, or RAG. This is your best friend. Instead of letting your AI guess the answer to something like "what is agentic ai", you force it to look up real facts in a trusted database. It is like giving a student an open book test. They have to cite the right page. This is a proven way to reduce LLM hallucinations in enterprise applications by grounding every answer in reality.
Second, you need verification layers. This means using one tool to check the AI’s work. You might run a consistency check or use a second model to scan for made-up facts before they turn into actions. Research on AI SRE agents shows that treating your AI like production software and validating its outputs catches errors before they cause damage.
Third are guardrails. These are the hard rules your agent cannot break. For example, if you use generative AI services to support customers, a guardrail might say "never share billing details." If you use coding AI, a guardrail might say "never modify the live database." The NIST AI Agent Standards Initiative is helping define exactly how to set these boundaries safely.
These three layers work together to build a trustworthy system. For developers working directly with code, understanding the specific risks is crucial. Read more about AI hallucinations in coding to protect your deployments.
Hallucinations are also a trust problem. Read AI Risk Smarter to build confidence into every layer of your agentic system.
H3: Operational Mitigations: Logging, Monitoring, and Testing
Even with strong architectural safeguards, you can’t just set and forget your AI. You need to keep an eye on it every day.

Think of it like this. You built a strong house with locks and alarms. That is your architecture. But you also need to check who comes in and out. That is your operations.
Here is how you keep things running smoothly.
Logging is your memory. You need a detailed record of every action your AI agent takes. What did it see? What did it decide? What did it do? This record lets you go back after something goes wrong and figure out why it happened. Without it, you are just guessing. Treating these systems like production software is the first step to catching errors early, as the Neubird guide on AI SRE guardrails explains.
Monitoring gives you a live dashboard. Set up real time alerts that go off when your AI is too uncertain. Maybe the confidence score drops below a safe level. Maybe it tries to access a file it should not touch. When this happens, a human gets pinged immediately. This is how you stop a bad decision before it becomes a big problem. The BrightFlow 2026 compliance overview highlights why these monitoring systems are now essential for regulatory safety.
Testing is how you find new weaknesses. You need to constantly poke and prod your own AI. This is called red teaming or adversarial testing. You try to trick it. You give it confusing prompts. You ask it to do things it should not do. The goal is to uncover new hallucination patterns before a real user stumbles into them. For example, rigorous testing of a coding AI can catch made up functions or unsafe code before it hits production. The Department of Defense guidance on agentic AI adoption specifically recommends this continuous testing for any high stake system.
These three practices, logging, monitoring, and testing, turn your AI from a black box into a manageable system. You see what it does, you intervene when it wobbles, and you constantly stress test its limits. That is how you build true operational confidence.
Hallucinations are also a trust problem. Read AI Risk Smarter to build confidence into every layer of your agentic system.
The Future of Reliable Agentic AI
You have learned how to log, monitor, and test your AI today. But the field of agentic AI is moving fast. What comes next is even more exciting for anyone who wants dependable systems.
Emerging approaches are changing the game. Researchers are building neuromorphic architectures that mimic the human brain. They are creating self-checking models that catch their own hallucinations before they cause harm. And they are developing formal verification tools that prove an agent’s plan is safe before it ever executes. The IBM definition of agentic AI explains why these autonomous systems need this kind of precision. These methods are not science fiction. They are being tested right now in labs and production environments.
Regulation is catching up too. In 2026, governments are starting to require detailed hallucination reporting for high-risk agentic systems. The UK government’s AI insights highlight the need for transparency when AI acts on its own. The ITIC industry document also points to standardized reporting as a must for building trust. This means your team will need to document every accuracy check and failure mode.
Why this all matters. Reliable agentic AI is the only way to safely automate critical tasks in healthcare, finance, and infrastructure. One wrong output could mean a wrong diagnosis, a bad trade, or a power grid failure. Getting the foundation right is not optional.
To stay ahead, keep exploring how new models like Realistic AI Models reduce hallucinations today. Then Read AI Risk Smarter to build trust into every layer of your agentic system.
Summary
This article explains what agentic AI is—autonomous, goal-driven systems that perceive, plan, and act with minimal human input—and why that shift from generative outputs to independent actions raises the stakes for hallucinations and trust. It walks through the core architecture (perception, reasoning, planning, execution and orchestration), shows how errors like tool-calling faults, planning hallucinations, and context contamination cascade, and gives real-world examples from navigation, coding, and customer service. The piece quantifies the impact with industry cost figures and project-failure rates, then lays out practical mitigation strategies: retrieval-augmented grounding (RAG), verification layers, hard guardrails, human-in-the-loop controls, and operational practices such as logging, monitoring, adversarial testing, and red teaming. It also covers architectural advice—constrained decoding, verification models—and explains why continuous testing and clear audit trails are essential for compliance and safety. Finally, the article points to emerging research and regulatory trends that will shape how teams build reliable agentic systems and reduce the chance that confident but false AI actions cause real harm.